



![Git undo merge [a Git commands tutorial]](https://cdn.prod.website-files.com/61c02e339c11997e6926e3d9/61c2e47fe7b34f78a82f31c6_5e06525cbe0f824a456d9a68_git%2520undo%2520merge.jpeg)

{{text-cta}}
Why undo merge
Occasionally, you can get into a situation where you make a merge, commit it, and maybe even push it to your remote server before realizing there’s an issue with it. When this happens, you’ll need a way to get your main branch back to its previous state.
If you were still in the merge process, you could run git merge --abort to cancel the merge - Git cleans up everything nicely and you’d end up in the state your main branch was in before.
However, if you’ve already finished your merge, there’s no such option. Instead, here’s what you’ll need to do: first, make sure you check out the main branch that you merged your changes into. You’ll want the next steps to affect this branch.
Next, find the commit hash of the merge with git log:
That will generate a list of commits that looks something like this:
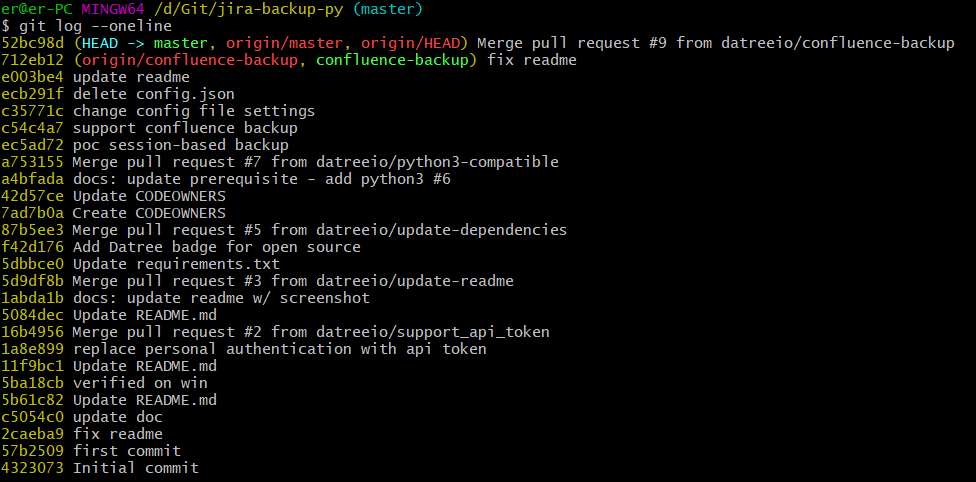
The commit hash is the seven character string in the beginning of each line. In this case, `52bc98d` is our merge’s hash. Once you have that, you can pass it to the git revert command to undo the merge:
And Bob’s your uncle! The git revert command will have generated a commit that restores your branch’s state to where it was before the faulty merge. If your merge was remote (i.e. happened on GitHub) you can push this commit like any other and you’ll be set to go.
How does reverting a merge work?
As it does with regular commits, Git creates merge commits with a commit hash representing the point in history where the other branch was merged in. We can use this information to run the git revert command to restore your branch to the state that it was in previously.
git revert generates a series of changes that, when applied, produce the exact inverse of whatever commit you give to it, then creates a new commit with those changes. This means that both the original commit and the new inverse commit will both be stored in history, preserving all of the data about what happened but leaving your branch in the state it was before you made the first commit.
Due to the way merges work, you have to do a little extra work, though. Normally, you can feed git revert the hash of the commit you want to undo, and Git will then look at that commit’s pointer to its parent commit to determine which changes to revert.
However, because a merge commit by nature has two parent commits (one from each branch you are merging together), you need to specify which parent is the “mainline” -- the base branch you merged into.
That’s where the -m flag comes in -- passing in a 1 points it to the branch that you had checked out when you began the merge (passing in a 2 would point to the branch that was merged in, which isn’t useful in our case). The docs for `revert` explain how that works here.
{{text-cta}}
Reapplying a reverted merge
A common workflow need after you revert a faulty merge is to continue working on the branch and re-merge it later.
Unfortunately, you can’t directly do that. If you try, you’ll find that the commits from the first merge of the branch that you already reverted won’t be reapplied after the second merge. The commits in the branch that was merged are permanently reverted, so if you attempt to re-merge a reverted branch without rebuilding those commits, those changes won’t be applied the second time.
Linus Torvalds, the creator of Git, explains why this happens (emphasis mine):
"Reverting a regular commit just effectively undoes what that commit did, and is fairly straightforward. But reverting a merge commit also undoes the _data_ that the commit changed, but it does absolutely nothing to the effects on _history_ that the merge had. So the merge will still exist, and it will still be seen as joining the two branches together, and future merges will see that merge as the last shared state - and the revert that reverted the merge brought in will not affect that at all."
"A `revert` undoes the data changes, but it's very much _not_ an `undo` in the sense that it doesn't undo the effects of a commit on the repository history. So if you think of `revert` as `undo`, then you're going to always miss this part of reverts. Yes, it undoes the data, but no, it doesn't undo history."
You can read the full documentation on handling faulty merges here. It gets much more in-depth than this article does, but here’s the tl;dr on what you actually need to do from lower down the page:
"If the faulty side branch was fixed by adding corrections on top, then doing a revert of the previous revert would be the right thing to do."
"If the faulty side branch whose effects were discarded by an earlier revert of a merge was rebuilt from scratch (i.e. rebasing and fixing, as you seem to have interpreted), then re-merging the result without doing anything else fancy would be the right thing to do."
Taking preventative measures to avoid merge reversions
Reverting merges is a messy business. It’s time-consuming, confusing, and results in a less clear Git history. As your codebase grows, you may want to take preventative measures to avoid having to revert merges unnecessarily.
For example, you may want to improve or set up your code review process. You can also define code owners to make sure the appropriate eyes are on your pull requests before they get merged.
Finally, a tool like Datree can also be extremely useful to establish guidelines across multiple repositories as your organization grows.
Learn from Nana, AWS Hero & CNCF Ambassador, how to enforce K8s best practices with Datree

Headingajsdajk jkahskjafhkasj khfsakjhf
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.

%20(1).webp)
.png)
.png)





